
In 2026, data teams aren’t judged by “knowing tools” - they are judged by speed to insight, reliability and business outcomes. Data volume is growing, decisions are expected faster, and AI copilots are everywhere. But one thing hasn’t changed: the people who win are the ones who can extract clean data → explain insights → ship something usable.
This blog gives you the Top 10 Data Science Tools for 2026, plus a role-based stack (so you learn only what matters) and a short workflow that shows how these tools connect in real work.
How Data Science Workflows Changed (Then vs Now)

Learning in this field is rapidly evolving with AI, cloud computing, and automation. Gone are the days of manual processing—there is a quick shift to AI-driven Data Science Tools and cloud platforms, making learning more accessible. Emerging technologies like AutoML and Agentic AI help simplify workflows for professionals. As the demand for skilled experts grows, mastering these Data Science Tools is the only way to stay ahead.
Data Science Previous Scenario of Learning
Earlier, learning about Data Science Tools was linear and manual:
- Data Collection: Raw data was cleaned manually without advanced Data Science Tools.
- Exploratory Data Analysis (EDA): Relying on basic libraries before the modern Data Science Tools ecosystem matured.
- Model Training: Writing long-form code was common before Data Science Tools automated model training.
- Deployment: Setting up complex infrastructure was a hurdle for any career in data science.
Data Science Current Scenario of Learning
Today’s scenario uses AI and cloud tools to automate workflows. The challenges of manual manipulation and scalability are solved by modern Data Science Tools. AI-powered cloud platforms and AutoML tools now simplify model selection and deployment. With these advancements, the future of a career in data science is more efficient and accessible for beginners.
Data Science vs Machine Learning (Quick Clarity)
| Aspect | Data Science | Machine Learning |
| Goal | Insights + decisions + reporting + experimentation | Pattern learning + prediction/automation |
| Scope | Wider (data → dashboards → metrics → models) | Narrower (model-building focus) |
| Common Tools | SQL, Excel, BI tools, Python analytics | scikit-learn, PyTorch/TensorFlow, MLOps |
| Output | KPIs, reports, experiments, decision support | Models, APIs, automation pipelines |
In real companies, most “data science work” starts as data science (SQL + KPIs + story) and only sometimes becomes ML.
Top 10 Data Science Tools in 2026
Grouped by Workflow
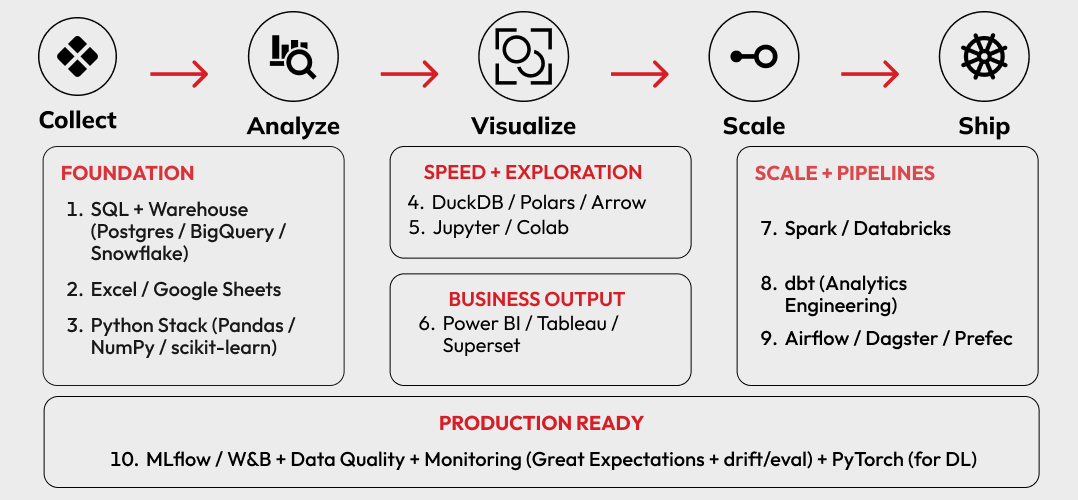
These are the tools (and tool-families) that show up again and again in real teams.
1. SQL + A Warehouse (Your Career Accelerator)
Best for: extraction, joins, clean metrics, reproducible logic
- PostgreSQL / MySQL (core)
- BigQuery / Snowflake / Redshift (modern orgs)
If you are serious about getting hired, SQL is not optional — it is the foundation.
2. Spreadsheets (Yes, Still)
Best for: quick analysis, stakeholder-friendly reporting, lightweight ops tracking
- Excel / Google Sheets
In 2026, spreadsheets are still the “last-mile interface” for many teams.
3. Python Analytics Stack (The Daily Workhorse)
Best for: cleaning, EDA, feature building, automation
- Pandas / NumPy (core)
- scikit-learn remains a major “default” library for traditional ML workflows.
4. Fast Local Analytics: DuckDB / Polars / Arrow (When Data Gets Big)
Best for: working with larger datasets locally without spinning up clusters A growing pattern is using DuckDB/Polars for faster analytics where pandas slows down (especially for larger files and heavy transforms).
(You don’t need to “replace pandas” — just know when to use what.)
5. Notebooks (Learning + Prototyping)
Best for: experiments, demos, teaching, shareable analysis
- Jupyter / Google Colab
Notebooks remain the fastest way to explore and communicate analysis.
6.BI + Dashboards (Where Hiring Happens)
Best for: KPI visibility, stakeholder reporting, decision-making
- Power BI / Tableau / Apache Superset
If you want faster job outcomes (especially analyst/BI roles), dashboards are one of the strongest signals.
7. Distributed Compute + Lakehouse Platforms
Best for: huge data, parallel processing, scalable pipelines
- Apache Spark / PySpark is still one of the most common engines for large-scale processing.
- Databricks is commonly used in “lakehouse” setups (Spark-centric).
8. Data Transformation Layer (Analytics Engineering)
Best for: clean, reusable metrics and models in SQL
- dbt (common standard in analytics engineering)
This is how teams stop rewriting the same SQL logic everywhere.
9. Orchestration (Make Work Repeatable)
Best for: scheduled pipelines, dependencies, automation
- Airflow / Dagster / Prefect
If your analysis must run daily/weekly reliably, orchestration becomes the backbone.
10. MLOps + Quality + Monitoring (Production Reality)
Best for: tracking experiments, versioning, data quality, drift/monitoring
- MLflow / Weights & Biases (tracking)
- Great Expectations (data quality checks)
- Evidently-like monitoring patterns are increasingly expected in production workflows (especially when models go live)
Also: PyTorch continues to be a “load-bearing” deep learning framework with strong ecosystem momentum.
Tool Stack by Role
Pick Your Path
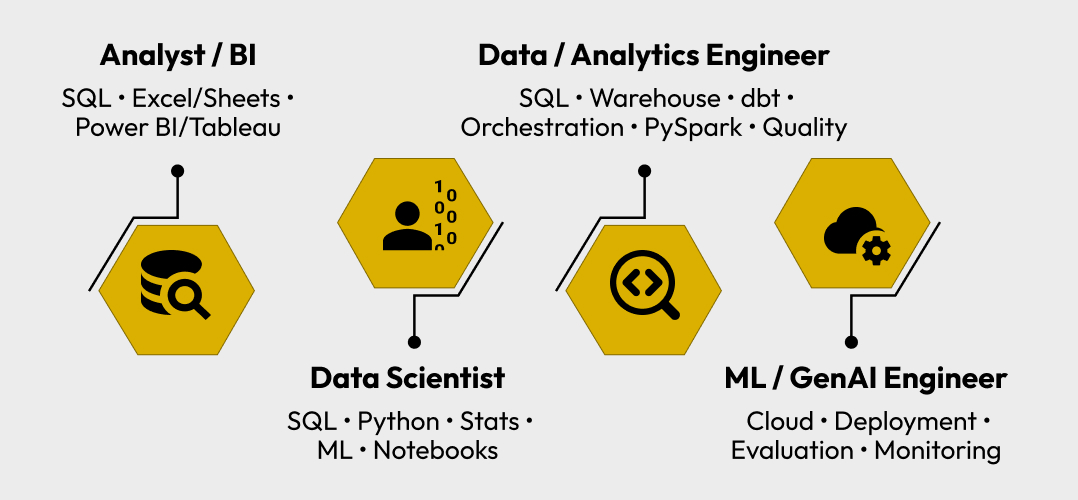
This section saves readers from learning tools randomly.
If you’re targeting Data Analyst / BI
SQL + Excel/Sheets + Power BI/Tableau + KPI thinking Optional: basic Python for automation.
If you’re targeting Data Scientist
SQL + Python (Pandas/NumPy) + stats + ML basics + notebooks Add: tracking (MLflow/W&B) when projects get serious.
If you’re targeting Data Engineer / Analytics Engineer
SQL + warehouse + dbt + orchestration + PySpark + data quality You’ll be judged on reliability and scale.
If you want an edge in ML/GenAI roles
Cloud basics + deployment exposure + evaluation mindset GenAI is everywhere, but teams still care about correctness, monitoring and trust.
How to Choose Tools (3 Quick Questions)
Before you pick a tool, ask:
- What role am I targeting? (Analyst vs DS vs DE changes everything)
- How big is the data? (fits on laptop vs needs cluster)
- Do I need production reliability? (one-time analysis vs scheduled pipeline)
If you answer these three, your tool choices become obvious.
A Real Workflow Example
Let’s say a company wants to reduce churn or improve retention:
- SQL + Warehouse: extract clean customer + activity tables
- Python (Pandas/Polars): clean, join features, run EDA
- BI Dashboard: show churn by plan, region, onboarding stage
- Model (optional): baseline churn prediction (scikit-learn)
- Deploy + Monitor (if ML): API + monitoring + drift checks
In-Demand Skills for 2026 What Companies Filter For
These are the skills companies consistently shortlist on:
- SQL (must-have): joins, window functions, clean queries
- Python for data work: Pandas/NumPy, visualization, ML basics
- BI + dashboards: Power BI / Tableau / Superset + KPI building
- Statistics & experimentation: distributions, hypothesis testing, A/B basics
- Data engineering basics: ETL/ELT, PySpark fundamentals, data quality checks
- Cloud basics: AWS/Azure/GCP storage + notebooks + deployment exposure
- GenAI basics (bonus edge): embeddings + RAG understanding, evaluation mindset
- Communication: storytelling, decision-ready reporting
These skills are what turn “learning” into employability.
Data Science Job Market in 2026 (Role-Specific Hiring)

Hiring is strong but more role specific. Companies want outcomes, not certificates.
High demand tracks:
- Data Analyst / BI: fastest hiring (SQL + dashboards)
- Data Scientist: modeling + business impact (Python + stats + ML)
- Data Engineer / Analytics Engineer: pipelines + quality + scale (SQL + ETL + PySpark)
- ML/GenAI roles: deployment + monitoring + evaluation (cloud + MLOps + LLM ecosystem)
FAQ (Real Questions People Ask in 2026)
1) “What should I learn first so I don’t waste time?”
Start here: SQL → Excel/Sheets → Power BI/Tableau → Python (Pandas) → stats → ML basics → cloud basics.
2) “I know Python, but I’m still not getting shortlisted. Why?”
Most rejections happen due to weak SQL + no business-ready projects + poor storytelling. Build 2–3 projects with a clear outcome and show the dashboard/report.
3) “Do I need GenAI tools for data science jobs in 2026?”
Not mandatory for entry roles, but it’s a strong advantage. Basic embeddings + RAG + evaluation mindset helps you stand out.
4) “Power BI or Tableau — I can learn only one.”
If you must pick one first: Power BI (wider adoption in many teams). Tableau becomes easy later.
5) “What portfolio projects actually work in 2026 (not Titanic)?”
Do business-like projects:
- SQL + KPI dashboard
- Python EDA + insights report
- Forecasting/churn model with a clear business explanation Bonus: “Ask My Data” mini RAG project + evaluation notes.
Final Take: Don’t Collect Tools — Build a Stack
You don’t need 50 tools. You need a stack that matches your target role & 2–3 projects that prove you can deliver outcomes.