
Your RAG system won’t be better than the information you can supply to the LLM. There’s a growing realization that the context of the LLM is a sparse resource that must be spent intelligently, as seen in the sudden popularity of the term context engineering:
in every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window with just the right information for the next step. - Andrej Karpathy
Part of this is retrieving just the right information (the green chunks) to add to the context - no more and no less.
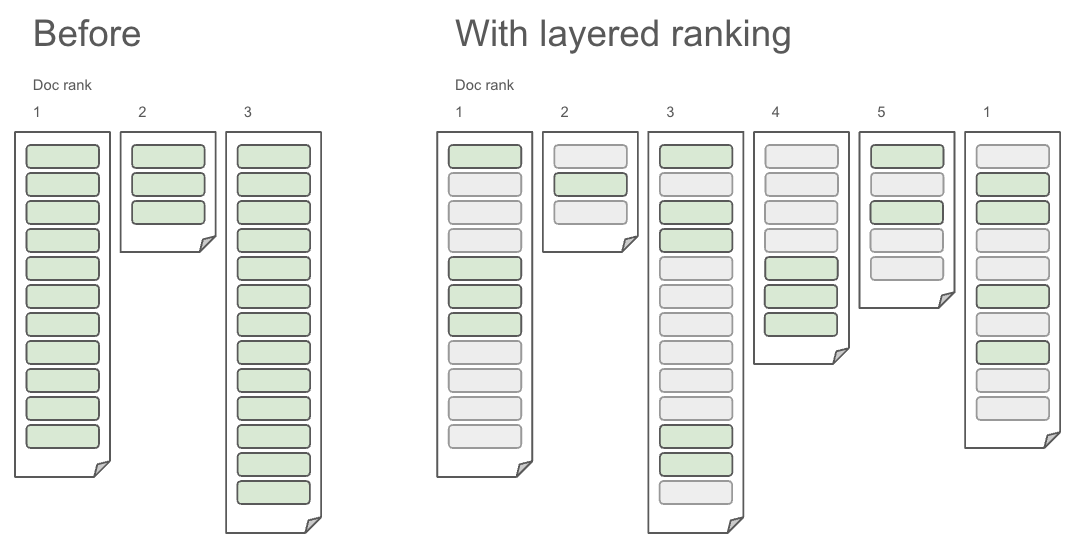
Until now, RAG systems have relied purely on document ranking to populate the LLM context: The entire top N ranked documents are retrieved to add to the context. In Vespa 8.530 we’re for the first time changing this paradigm in retrieval systems by introducing layered ranking, where ranking functions can be used both to score and select the top N documents, and also to select the top M chunks of content within each of those documents. This second layer ranking happens distributed in parallel on the content nodes storing those documents, which ensures this scales with constant latency to any query rate and document size.
This allows you to efficiently and flexibly choose the most relevant pieces from a larger set of documents rather than being forced to choose between fine-grained chunk-level documents missing context, or requiring the LLM to deal with a large context containing irrelevant information:
Before layered ranking, you had two options, both bad:
| Pro | Con | |
| Chunk-level documents | - Only the most relevant chunks are selected | - Documents lack context relevant for ranking - Document-level metadata must be duplicated - Expensive due to producing very large document sets |
| Multi-chunk documents | - Chunks can be scored with full context - No metadata duplication - No document count explosion | - All chunks of each document are selected, leading to large context windows with irrelevant information, and excessive bandwidth usage with large documents |
With layered ranking, we get the best of both:
| Multi-chunk documents | - Chunks can be scored with full context - No metadata duplication - No document count explosion - Only the most relevant chunks of each document are selected, leading to optimal use of resources and the LLM context window |
Here’s an example Vespa schema using the new layered ranking to select the best chunks of each document in addition to selecting the best documents:
schema docs {
document docs {
field embedding type tensor<float>(chunk{}, x[386]) {
indexing: attribute
}
field chunks type array<string> {
indexing: index | summary
summary {
select-elements-by: best_chunks
}
}
}
rank-profile default {
function my_distance() {
expression: euclidean_distance(query(embedding), attribute(embedding), x)
}
function my_distance_scores() {
expression: 1 / (1+my_distance)
}
function my_text_scores() {
expression: elementwise(bm25(chunks), chunk, float)
}
function chunk_scores() {
expression: join(my_distance_scores, my_text_scores, f(a,b)(a+b))
}
function best_chunks() {
expression: top(3, chunk_scores)
}
first-phase {
expression: sum(chunk_scores())
}
summary-features {
best_chunks
}
}
}Notice that:
Ranking scores for both vector similarity and lexical match are calculated per chunk.
- These scores are combined (here:sum) to capture an aggregated score per chunk, and the sum of these makes up the total document score. This could also be a completely different scoring function, not relying on chunk scores.
- The chunks summary field is capped (here to top 3) using the new select-elements-by summary function, which points to the chunk scoring function used to select them.
Underlying this are new general tensor functions in Vespa’s tensor computation engine that allow filtering and ordering of tensors:
as well as a new composite tensor function using those:
and the elementwise bm25 rank feature:
You can experiment with this in Tensor Playground.
We believe this will revolutionize the quality we see in industrial-strength RAG applications, and our largest production applications where high quality and scale is critical are already busy putting it to use.updated 2